Programmation fonctionnelle en JavaScript
Bien que la programmation fonctionnelle ne date pas d’hier, on en entend de plus en plus parler. Souvent entourée de termes obscurs et de notions mathématiques complexes, on se dit qu’on se penchera sur ce nouveaux paradigme de programmation un peu plus tard… Et si ce plus tard était maintenant ? Tentons d’aborder le FP de manière concrète et pragmatique.
Comme souvent, certaines personnes n’admettent pas que l’on puisse prendre quelques largesses dans l’application réelle d’un champ académique. Le JavaScript n’étant pas un langage conçu spécifiquement pour la programmation fonctionnelle, nous verons ici les principales notions et les applications utiles en vrai.
Il existe cependant des langages conçus spécifiquement pour la programmation fonctionnelle et qui compilent en JavaScript. Aussi, si vous désirez une programmation purement fonctionelle sans compromis, peut-être devriez-vous vous tourner vers Elm ou ClosureScript.
De quoi s’agit-il ?
Avant d’en expliquer les notions, commençons par définir la programmation fonctionnelle.
La programmation fonctionnelle est un paradigme de programmation de type déclaratif qui considère le calcul en tant qu’évaluation de fonctions mathématiques.
Comme le changement d’état et la mutation des données ne peuvent pas être représentés par des évaluations de fonctions la programmation fonctionnelle ne les admet pas, au contraire elle met en avant l’application des fonctions, contrairement au modèle de programmation impérative qui met en avant les changements d’état.
Tout n’est pas forcement limpide, mais on comprend déjà que la PF – je l’appellerai comme cela dorénavant dans l’article pour plus de brieveté – est un paradigme de programmation au même titre que le programmation orientée objet ou la programmation procédurale.
Contrairement aux paradigmes de programmation du type impératif, dans lesquels on décrit les différentes actions à réaliser, la programmation fonctionnelle est un sous-type de la programmation déclarative, laquelle vise à définir les données du problème et le résultat attendu plutôt que les étapes pour arriver au résultat.
La programmation déclarative signifie que tout est fait avec des expressions (quelque chose qui retourne une valeur) et non des instructions (statement en anglais) (plus petit élément qui exprime une action), lesquelles sont exécutées pour leurs effets de bord.
L’avantage de la programmation fonctionnelle est d’aboutir à un code plus expressif, facilement maintenable et testable. Voyons maintenant quels en sont les principes.
Des fonctions pures
Un des principes de base de la PF est d’éviter les effets de bord. C’est à dire qu’une fonction ne doit pas modifier des choses en dehors de son propre scope (sa portée), tel qu’accéder ou modifier une variable extérieure à elle-même.
Cela permet de rendre le code plus prévisible car à sa lecture, il est immédiatement possible d’identifier les causes et les effets.
Une fonction qui modifie des variables non locales doit être lue dans son intégralité pour savoir ce qu’elle fait et il est difficile d’en connaitre l’impact réel (quelles autres fonctions dépendent/touchent à ces variables ?).
Une fonction pure prend donc une ou des valeurs en arguments et retourne une valeur.
let userAge = 20;
// cette fonction est impure
function addYear() {
userAge += 1;
}
addYear();
console.log(userAge); // 21Cette fonction n’est pas pure car elle accède à une variable libre (une variable non locale) et elle modifie cette dernière. D’autres fonctions qui nécessiteraient la valeur contenue dans userAge pourraient disfonctionner car ne pas s’attendre à ce que la valeur ait changée. En outre, chaque appel à cette fonction mène à un résultat différent.
const userAge = 20;
// cette fonction est pure
function addYear(userAge) {
return userAge + 1;
}
console.log(addYear(userAge)); // 21
console.log(addYear(userAge)); // 21
console.log(userAge); // 20Une fonction pure a toujours la transparence référentielle comme qualité. Ce terme signifie qu’il est possible de remplacer l’expression par son résultat sans changer le fonctionnement du programme.
const userAge = 18;
// cette fonction est pure et possède la transparence référentielle
function canBuyAlcohol(userAge) {
if (userAge >= 18) return true;
return false;
}
// on peut donc remplacer l'appel à canBuyAlcohol
if (canBuyAlcohol(userAge)) {
// on procede à la vente
}
// par son résultat
if (true) {
// on procede à la vente
}Autant le dire tout de suite, bien que les fonctions pures constituent un élément central de la PF, nous sommes obligé d’avoir certaines fonctions impures, sinon le programme ne sert à rien. Écrire sur le disque, faire des requêtes réseau, modifier le DOM… sont autant d’effets de bords qu’un programme a besoin d’effectuer.
Dès lors, il s’agira de limiter ces fonctions impures au maximum afin de pouvoir facilement les identifier et de faciliter la lecture du code.
Enfin, les fonctions pures sont thread safe puisqu’elles ne dépendent pas de la mémoire partagée et ne soufrent pas de race conditions dû à l’absence d’effets de bord. Il est donc très simple de les paralléliser.
L’immutabilité
En PF, il n’y a pas de variables à proprement parler. Lorsqu’une variable prend une valeur, elle ne doit plus changer. Cela signifie qu’il est illégal de .push sur un tableau de i++ dans une boucle ou encore de changer l’attribut d’un objet user.connected = true.
Lorsqu’on lit ça pour la première fois, on se dit, “ok, c’est n’importe quoi”. Les variables sont une notion fondamentale en programmation et si elles s’appellent variable, c’est bien que leurs valeurs peuvent varier.
En PF, on ne modifie jamais une variable après sa déclaration. Pourtant, un programme dans lequel il n’y a aucun changement de valeurs ne fait pas grand chose… Comment fait-on pour tracker les changements de valeurs dans un programme alors ? En PF, chaque nouvelle valeur se voit attribuer une nouvelle variable.
On a vu apparaître en ES2015 le mot-clef const, spécifiant que la variable déclarée est une constante. Ainsi, si l’on fait const age = 10; puis plus loin, age = 11;, le moteur JavaScript refusera de modifier la constante et lèvera une erreur. Le fonctionnement est similaire avec les chaînes de caractères.
Cependant, les tableaux et les objets ne fonctionnent pas tout à fait de la même manière.
const students = ['jean', 'antoine', 'marcel'];
students = ['fred', 'louis', 'fabien']; // erreur, tout va bien
students.push('claire'); // ok
console.log(students); // ['jean', 'antoine', 'marcel', 'claire']
// idem avec les objets
const claire = {
fname: 'Claire',
lname: 'Dupond',
age: 16
};
claire.age = 17; // fonctionne très bienLe JavaScript est un langage orienté objet à prototype et n’a pas vraiment été conçu pour l’immutabilité. On pourra partiellement (premier niveau seulement) s’assurer de l’immutabilité des objets avec Object.freeze, mais ce n’est pas la solution ultime.
Ainsi, si certaines méthodes facilitent l’immutabilité car elles retournent une nouvelle valeur, beaucoup d’autres modifient directement la variable.
// méthodes qui retournent une nouvelle valeur sans toucher à la variable originale
const merged = array.concat(arr1, arr2);
const filtered = array.filter(fn);
const mapped = array.map(fn);
// méthodes qui mutent la variable
array.push('newval');
array.pop();
array.sort();Dans un langage fonctionel, aucune méthode ou fonction ne viendra jamais modifier la variable sur laquelle elle agit. En JS, pour contourner cela et se conformer à l’immutabilité, on peut créer une nouvelle variable en copiant tous les éléments de la précédente.
function addStudent(students, newStudent) {
return [...students, newStudent];
}
const updatedStudents = addStudent(students, 'jérôme');
console.log(students); // ['jean', 'antoine', 'marcel']
console.log(updatedStudents); // ['jean', 'antoine', 'marcel', 'jérôme']
function loginUser(user) {
let newUserRecord = Object.assign( {}, user );
newUserRecord.loggedIn = true;
return newUserRecord;
}
const user = {
fname: 'Claire',
lname: 'Dupond',
age: 16,
loggedIn: false
};
const loggedInUser = loginUser(user);
console.log(user); // { fname: "Claire", lname: "Dupond", age: 16, loggedIn: false }
console.log(loggedInUser); // { fname: "Claire", lname: "Dupond", age: 16, loggedIn: true }La variable passée en paramètre n’est pas modifiée, on créé une nouvelle variable au lieu de muter celle passée en référence. Par ailleurs, vous noterez qu’on opère quand même une mutation ligne 12.
Académiquement parlant, ce ne serait surement pas tolérable, cependant, notre fonction est toujours pure dans le sens ou elle possède la caractéristique de transparence référentielle.
En ES2018, on pourrait éviter de muter notre objet en utilisant le spread operator :
const newUserRecord = {...user, loggedIn: true };Une question vous vient peut-être à l’esprit : quid de la performance ? Conserver tous les éléments en mémoire et en effectuer des copies dès lors que l’on veut les modifier consomme du CPU et de la RAM, d’autant plus que les variables contiennent de nombreux éléments.
Cette préocupation est tout à fait fondée. Nativement, le JS n’est pas fait pour l’immutabilité et tout copier n’est pas efficace du tout.
C’est pourquoi les langages fonctionnels utilisent pour cela des structures de données persistantes, notamment des hash tries [en]. Cela permet de faire référence aux valeurs de la variable a pour toutes les données inchangées dans a'. Ainsi, a' ne contient réellement que les données nouvelles ou modifiées.
Pour un usage efficace de l’immutabilité en JavaScript, il faudra avoir recourt à une bibliothèque permettant de gérer ces structures de données, telle que Immutable.js ou Mori.
Fonction d’ordre supérieur
Cette notion, bien que très puissante, est très simple à définir et à comprendre. Autant directement citer notre encyclopédie favorite.
Les fonctions d’ordre supérieur sont des fonctions qui ont au moins une des propriétés suivantes :
- elles prennent une ou plusieurs fonctions en entrée ;
- elles renvoient une fonction.
En JavaScript, comme vous le savez certainement, une fonction est un objet comme un autre et il est très fréquent de passer des fonctions en argument, les callbacks en sont un des exemples les plus courants.
function hashPasswd(passwd, callback) {
// compute hash
callback(computedHash);
}
hashPasswd(passwd, (hash) => {
// on fait des choses avec le hash
}On a cependant moins l’habitude d’avoir des fonctions comme valeur de retour. Pourtant, dans un cas comme dans l’autre, les fonctions d’ordre supérieur peuvent s’avérer très utile pour DRY, c’est à dire écrire le moins possible.
const l18n = {
en: {
hello: 'Hello',
ciao: 'See you'
},
es: {
hello: 'Hola',
ciao: 'Hasta luego'
},
fr: {
hello: 'Bonjour',
ciao: 'À bientôt'
}
};
function saySomethingToUser(l18n, locale, sayWhat) {
return userName => `${l18n[locale][sayWhat]} ${userName}`;
}
const sayHelloInFrench = saySomethingToUser(l18n, 'fr', 'hello');
const sayCiaoInSpanish = saySomethingToUser(l18n, 'es', 'ciao');
console.log(sayHelloInFrench('Jean'));
console.log(sayCiaoInSpanish('Juan'));Cette manière de retourner des fonctions permet très facilement de construire des fonctions plus spécifiques et d’éviter d’avoir à passer trop de paramètres. En effet, la fonction retournée “se souvient” des paramètres passés à la fonction parente, il s’agit d’une closure.
Composition de fonctions
DRY un jour, DRY toujours ! La logique de ne pas se répéter est centrale en programmation et encore plus en programmation fonctionnelle. Tel que nous l’avons vu avec les fonctions d’ordre supérieur, utilisées pour construire des fonctions plus spécifiques afin de ne pas se répéter. C’est également ce que nous allons faire avec la composition de fonctions.
Il faut voir nos fonctions comme des briques de Lego. Une fonction simple qui ne fait qu’une chose aura plus de chance d’être réutilisée qu’une fonction complexe qui ne sert que dans un cas particulier.
// nous avons deux élèves dont nous voulons calculer la moyenne
const studentAGrades = [4, 7, 6, 1, 6, 6, 9];
const studentBGrades = [3, 9, 6, 6, 5, 0, 2];
// évidemment, on peut faire une fonction de calcul de moyenne
function computeMean(grades) {
let sum = 0;
grades.forEach(grade => {
sum += grade;
});
return sum / grades.length;
}
// mais en PF, nous voulons avoir de petites fonctions réutilisables
function sum(numsArr) {
let sum = 0;
numsArr.forEach(nums => {
sum += nums;
});
return sum;
}
// tiens, une fonction d'ordre supérieur
function divideBy(divisor) {
return dividend => dividend / divisor;
}
// tous les élèves ont le même nombre de notes
const divideByNumberOfExams = divideBy(studentAGrades.length);
// usage de manière naïve
const sumOfGrades = sum(studentAGrades);
console.log(divideByNumberOfExams(sumOfGrades)); // 5.571428571428571
// on peut faire un peu mieux en imbriquant les fonctions
console.log(divideByNumberOfExams(sum(studentAGrades))); // 5.571428571428571
// mais c'est ch***t et peu lisible d'imbriquer tous ces arguments à chaque fois
// avec la composition de fonctions, on peut créer une nouvelle ƒ plus spécifique
const computeMeanComposed = grades => divideByNumberOfExams(sum(grades));
// la même chose en éliminant l'usage d'une variable pour divideByNumberOfExams
const computeMeanComposed2 = grades => divideBy(studentAGrades.length)(sum(grades));
// l'appel est bien plus léger
console.log(computeMeanComposed(studentAGrades)); // 5.571428571428571
console.log(computeMeanComposed2(studentBGrades)); // 4.428571428571429
// et fonctionne exactement comme notre fonction computeMean
console.log(computeMean(studentBGrades)); // 4.428571428571429Évidemment, puisque nous avons déjà une fonction sum et une fonction divideBy, il est inutile d’écrire une fonction spécialisée depuis zéro. D’autant plus qu’elle ne nous resservira peut-être pas.
En revanche, si nous n’avons qu’un seul endroit de notre code où il nous faut calculer une moyenne, ce n’est peut-être pas la peine de composer une nouvelle fonction et on pourrait se contenter d’appels imbriqués.
Dans le cas de la composition, plus qu’une composition pure, nous déclarons ici une nouvelle fonction qui fait usage de nos deux fonctions pre-existantes. Cela est dû au fait que JS ne supporte pas la composition de fonctions nativement. C’est encore plus évident si l’on créé notre nouvelle fonction sans les fat arrows.
// lourd
const computeMeanComposed = function (grades) {
divideByNumberOfExams(sum(grades));
}Dans la trousse à outil du fonctional programmer, il existe un outil qui s’appelle compose. Il s’agit d’une fonction qui permet de créer une nouvelle fonction à partir de deux (ou plus) fonctions passées en paramètres.
const computeMeanComposed = compose(divideByNumberOfExams, sum);C’est plus clean non ? Vous remarquez que comme l’appel imbriqué, l’ordre d’appel est de droite à gauche (intérieur vers extérieur). C’est une convention en PF, on compose les fonctions dans le même ordre qu’on écrirait le code manuellement.
Vous retrouverez cette fonction dans la plupart des bibliothèques de PF. Voyons cependant à quoi ressemble son implémentation.
function compose(...fns) {
return function composed(result){
// on copie le tableau des ƒs passées en argument
const list = [...fns];
while (list.length > 0) {
// on prend la dernière fonction de la liste
// au prochain tour de boucle,
// fn suivante avec le résultat de la précédente
const fn = list.pop();
result = fn(result);
}
return result;
};
}Dernière petite remarque, vous avez peut-être noté que la fonction appellée en premier (celle de droite donc), peut potentiellement avoir une arité – le nombre d’arguments qu’accepte une fonction – supérieur à un, tandis que les autres doivent être unaires (un seul argument).
C’est d’ailleurs pour cela que nous utilisons divideBy plutôt que d’utiliser un utilitaire plus généraliste tel que divide, qui prendrait deux arguments à la fois. En effet, mis à part la première fonction appelée, toutes les autres reçoivent le résultat de la fonction précédente, et en JS une fonction retourne toujours une valeur unique.
Partial application
Comme je l’ai souligné précédemment, pour composer nos fonctions, leurs signatures doivent être compatibles. Nous avons cependant certains outils très efficace en PF pour nous aider dans cette tâche.
Avec l’application partielle (je ne suis pas certain de la justesse du terme en français), nous pouvons préciser certains arguments d’abord, puis le reste dans un second temps. Cela nous donne une certaine souplesse, d’autant plus que nous avons deux variantes : l’une pour commencer de gauche à droite, l’autre de droite à gauche.
// on reprend l'exemple précédent
...
function sum(numsArr) { ... }
// cette fonction générique n'est pas utilisable telle quelle
function divide(dividend, divisor) {
return dividend / divisor;
}
const divideByNumberOfExams = partialRight(divide, [studentAGrades.length]);
const computeMeanFP = compose(divideByNumberOfExams, sum);
computeMeanFP(studentAGrades);Et voilà, nous avons fait exactement le même travail qu’auparavant, mais en faisant usage de divide avec partialRight au lieu d’avoir créé une fonction divideBy plus spécialisée. L’application partielle permet de réduire l’arité d’une fonction en pré-renseignant certains arguments.
// observation intéressante
function divideBy(divisor) {
return dividend => dividend / divisor;
}
const partialDivide = divisor => partialRight(divide, [divisor]);
const by5 = divideBy(5);
const by5Bis = partialDivide(5);
if (by5(10) === by5Bis(10)) console.log('cool !'); // cool !Nous avons ici utilisé la console interactive de Ramda.
Nos outils partial et partialRight sont des fonctions d’ordre supérieur qui nous permettent de générer des fonctions plus spécialisées en pré-renseignant une partie des paramètres. Nous obtenons en retour une fonction dont la signature convient à notre composition !
La fonction partialRight que nous avons utilisé prend les paramètres dans un tableau, cela dépend de la bibliothèque utilisée et certaines acceptent les arguments séparémment. Voyons une implémentation de partial.
// on prend en paramètres la fonction et un tableau d'arguments
// on pourrait faire ...presetArgs pour avoir une signature avec fn, arg1, arg2, …
function partial(fn, presetArgs) {
// la fonction retournée accepte de nouveaux arguments
return function partiallyApplied(...laterArgs) {
// et on applique le tout à fn
return fn(...presetArgs, ...laterArgs);
};
}Currying
Maintenant que nous avons vu la partial application, voyons une autre technique assez similaire : le currying, ou curryfication en français. Wikipedia définit la curryfication comme suit.
En programmation fonctionnelle, la curryfication désigne la transformation d’une fonction à plusieurs arguments en une fonction à un argument qui retourne une fonction sur le reste des arguments.
Si ce n’est pas bien clair, tentons de définir la curryfication en la comparant à l’application partielle. Admettons que nous avons une fonction ternaire ƒa(x, y, z) (trois arguments). Nous faisons une application partielle en fournissant un seul argument, nous avons maintenant une nouvelle fonction binaire ƒb(y, z).
La curryfication transforme toute fonction non unaire en fonction unaire, laquelle retournera une fonction unaire acceptant l’argument suivant et ce, jusqu’au dernier. Ainsi, dans l’exemple de notre fonction ƒa(x, y, z), après curryfication, nous avons ƒb(y) qui retournera elle-même ƒc(z), laquelle retournera le résultat.
Illustrons tout cela en reprenant notre exemple de fonction qui permet de générer des messages dans plusieurs langues.
const l18n = { … };
function saySomething(l18n, locale, sayWhat, userName) {
return `${l18n[locale][sayWhat]} ${userName}`;
}
// on décompose ici toutes les étapes
const curriedSaySomethg = curry(saySomething);
const saySomeThg = curriedSaySomethg(l18n);
const saySomeThgInFrench = saySomeThg('fr');
const sayHelloInFrench = saySomeThgInFrench('hello');
console.log(sayHelloInFrench('Buzut')); // Bonjour Buzut
// mais bien entendu, rien ne nous oblige à passer par des variables intermédiaires
const saySomeThgInSpanish = curriedSaySomethg(l18n)('es');
const sayCiaoInSpanish = saySomeThgInSpanish('ciao');
console.log(sayCiaoInSpanish('buzut')); // Hasta luego Buzut
// ou encore
console.log(curriedSaySomethg(l18n)('en')('hello')('darling')); // Hello darlingVous voyez certainement que dans certaines situations, curry peut s’avérer fort pratique. Cependant, losque l’on veut passer plusieurs arguments à la fois, la notation JS qui oblige aux multiples parenthèses n’est pas des plus légère. C’est pourquoi certaines bilbiothèques permettent quand même de passer plusieurs arguments à la fois à une fonction curryfiée.
Ce dernier comportement rapproche sensiblement l’application partielle de la curryfication et donne un certain avantage à cette dernière. Par ailleurs, vous avez peut-être remarqué que dans le cadre d’une fonction binaire, l’application partielle et la curryfication reviennent au même.
Enfin, comme à notre habitude, voyons comment implémenter la fonction curry. Notre implémentation supporte le passage de plusieurs arguments à la fois.
// la propriété length d'une fonction donne son arité
// on permet optionellement de préciser l'arité
function curry(fn, arity = fn.length) {
return (function nextCurried(prevArgs) {
return function curried(nextArg) {
let args = [...prevArgs, nextArg];
// tant que l'arité n'est pas atteinte, retourne une nouvelle fonction
// qui récupèrera le (ou les) paramètres suivants
if (args.length >= arity) return fn(...args);
// sinon, on appelle la fonction finale avec tous les arguments
else return nextCurried(args);
};
})([]);
}Vous vous interrogez peut-être sur l’utilié de pouvoir préciser l’arité de la fonction. Bien que length donne normalement le nombre de paramètres, la propriété ne sera pas juste dans plusieurs cas :
- valeur par défaut,
- longueur d’argument variable (…args),
- parameter destructuring (affectation par décomposition in french).
Point free style
La programmation tacite, ou point free style est un style d’écriture des fonctions où, lors de l’appel de fonction, on ne spécifie pas explicitement les arguments sur lesquels la fonction travaille. Pour illustrer cela, reprenons notre exemple des notes d’étudiants, nous voudrions convertir les notes sur 20.
const studentAGrades = [4, 7, 6, 1, 6, 6, 9];
// on utilise la fonction multiply de notre trousse à outils PF
// je ne pense pas nécessaire de définir cette fonction…
const double = multiply(2);
// ici nous avons une fonction wrapper totalement inutile
const studentAGradesOn20 = studentAGrades.map(grade => {
return double(grade);
});
// la même chose en point free
const studentAGradesOn20PF = studentAGrades.map(double);
console.log(studentAGradesOn20); // [8, 14, 12, 2, 12, 12, 18]Il est évident que dans le second cas, notre calcul point free est bien plus concis et on s’évite du “bruit” totalement inutile. Cependant, on réalise avec cet exemple que le point free n’est possible que parce que les signatures coincident.
Il ne tient qu’à nous de les faire coincider et la trousse à outil du programmeur fonctionnel est pleine d’outils de ce type. Admettons que nous ne soyons pas certain que toutes les notes soient bien des nombres. Nous voulons nous en assurer via un utilitaire.
const studentAGrades = ['4', 7, '6', 1, '6', 6, 9];
// c'est une mission pour parseInt
// on est donc tenté de faire celà, point free baby…
const numberStudentAGrades = studentAGrades.map(parseInt);C’est une erreur qui mènera très certainement à des valeurs assez inattendues. C’est en effet sans prendre en compte la signature de parseInt(string, radix), ni les paramètres que map passe au callback(currentVal, index, originalArray).
On doit s’assurer que parseInt ne reçoit qu’un seul argument, sinon on ne serait plus en base 10. Pour cela, une fonction assez courante est unary. Son but est simple, elle s’assure que seul le premier argument est passé à la fonction. Tous les autres sont ignorés.
function unary(fn) {
// retourne une ƒ wrapper qui ne prend qu'un seul argument
return function(arg) {
// et appelle la ƒ fn passée en argument
return fn(arg);
};
}
// notre exemple précédent toujours point free mais qui cette fois fonctionne
const studentAGradesInt = studentAGrades.map(unary(parseInt));
// on n'oublie pas de doubler
const studentAGradesOn20 = studentAGrades.map(unary(parseInt))
.map(double);Dans le code précédent, on chaîne deux fonctions map. Cela fonctionne parfaitement, cependant, map boucle sur l’ensemble des valeurs. Ce n’est donc pas optimal de boucler deux fois. Une petite composition semble naturellement adaptée au cas présent.
const doubleAfterParseInt = compose(unary(parseInt), double);
console.log(studentAGrades.map(doubleAfterParseInt)); // [8, 14, 12, 2, 12, 12, 18]Nous avons ici une composition point free très expressive et qui nous permet également de gagner en performances.
La programmation tacite est à utiliser à bon escient. Dans certains cas, où lorsqu’elle est trop poussée, la lisibilité du code peut être altérée. C’est donc un concept à considérer au cas par cas lorsqu’il fait sens.
La récursion
La récusrion n’est pas l’apanage de la programmation fonctionnelle, cependant, ce concept est utilisé de manière récurrente en PF. En début d’article, j’expliquais qu’aucune variable ne doit changer de valeur, comment gérer une boucle dans ce cas ? Figurez-vous qu’en PF, les boucles n’existent pas.
Au lieu d’une boucle, une fonction peut s’appeler récusrivement jusqu’à ce qu’une condition soit remplie. Reprenons notre exemple de fonction sum, laquelle contient une boucle. Nous pouvons remplacer la boucle par des appels récursifs.
const studentAGrades = [4, 7, 6, 1, 6, 6, 9];
function sum(numsArr) {
let sum = 0;
numsArr.forEach(nums => {
sum += nums;
});
return sum;
}
// la même chose en utilisant la récursivité
function recSum(numsArr) {
// tant que l'array contient plus d'un élément
// on retourne la somme de l'élement courant au résultat du prochain appel
// avec en argument un nouvel array qui contient tous les éléments de numsArr moins le premier
if (numsArr.length > 1) return numsArr[0] + recSum(numsArr.slice(1, numsArr.length));
// si c'est le dernier élément, on retourne simplement l'élément en question
return numsArr[0];
}
recSum(studentAGrades); // 39Pile d’exécution
Au lieu d’avoir un suivi “manuel” de l’état, c’est ici géré par la pile d’exécution (call stack). Comme il s’agit d’une fonction pure, la transparence référentielle s’applique.
recSum(studentAGrades);
// est simplement égal à
4 + 7 + 6 + 1 + 6 + 6 + 9;
// la call stack évolue comme suit
// 4 + recSum([7, 6, 1, 6, 6, 9]);
// 4 + 7 + recSum([6, 1, 6, 6, 9]);
// …
// 4 + 7 + 6 + 1 + 6 + 6 + recSum([9]);
// 4 + 7 + 6 + 1 + 6 + 6 + 9;C’est la pile d’exécution qui garde trace des résultats des appels successifs et qui est en mesure de retourner le résultat final une fois que tous les appels ont été effectués.
On réalise à ces mots que chacun des appels doit être conservé en mémoire jusqu’à ce que l’ensemble des appels récursifs aient retourné leurs résultats. La mémoire n’est pas infinie et tous les systèmes (navigateurs, environnement server…) possèdent une limite du nombre de fonctions simultanément admises dans la call stack.
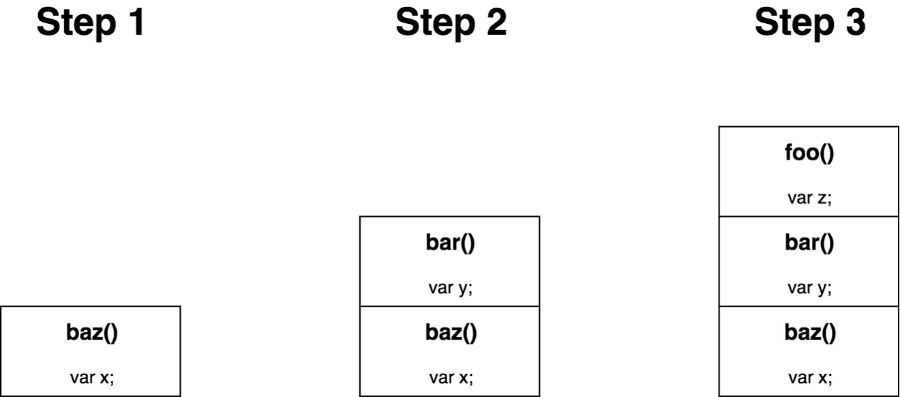
// permet de générer un array de grande taille contenant tous les nombre entre 0 et size
function range(size) {
return [...Array(size).keys()].map(i => i);
}
recSum(range(50000000));
// nodejs
// RangeError: Maximum call stack size exceededNodejs lèvera une erreur tandis que les navigateurs commenceront pas ramer avant de lever une erreur également. La récursion est-elle donc à abandonner en JavaScript ? Pas tout à fait, car c’est sans compter sur l’optimisation de la récursion terminale (tail calls).
Tail call optimisation
Lorsque l’appel récursif est la dernière instruction à être évaluée, la pile d’exécution n’a donc pas à garder en mémoire l’état des précédents appels. Dès lors, une fonction récursive qui profite de la TCO jouit d’une taille de pile fixe et chaque nouvel appel n’augmente pas la taille de la pile.
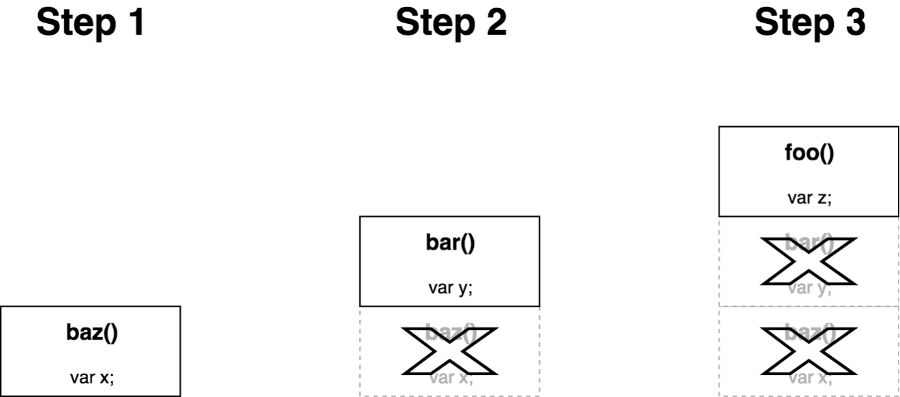
La PTC est respectée lorsque l’appel à fonction est la dernière chose à être exécutée dans la fonction appelante et que toute valeur est retournée explicitement. En d’autres termes :
function recurs() {
...
return recurs();
}Reprenons notre exemple précédent pour en faire une fonction respectant la PTC et donc éligible à la TCO.
// PTC
function sum(numsArr, acc) {
const curSum = acc + numsArr[0];
const nextArr = numsArr.slice(1, numsArr.length);
if (numsArr.length === 1) return curSum;
return sum(nextArr, curSum);
}Le problème avec cette implémentation est que l’on arrive rapidement à saturation mémoire à force de créer des copies de numsArr. En effet, je pense que le GC n’a pas le temps de libérer l’espace consommé par les variables appartenant à chaque fonction entre les appels.
Pour éviter ce problème, on peut éviter de créer à chaque fois une nouvelle variable et muter la variable passée en argument. Ici, dans la mesure où c’est un tableau, elle est passée en référence et nous n’avons donc qu’une seule et unique variable utilisée pour tous les appels successifs.
function sum(numsArr, acc) {
const curSum = acc + numsArr[0];
numsArr.shift();
if (numsArr.length === 1) return curSum;
return sum(numsArr, curSum);
}Il est également possible d’utiliser les structures de données persitantes dont nous avons parlé dans la partie concernant l’immutabilité. Cependant, et c’est là les limites de la PF avec des langages qui ne sont pas purement fonctionnels, on perd énormément en performance en JS avec la récursivité sur des traitements en nombre et utiliser des structures telles que les hash tries viendrait ralentir encore un peu plus notre programme.
En outre, tous les moteurs JS ne supportent pas la TCO, notamment V8, le moteur de Chrome et de Node.js. Bien que cette technique soit très intéressante, elle présente donc quelques limites dans certains cas. On l’utilisera donc avec précaution, surtout dans les cas où le nombre de récursions peut être important.
Functor
Nous avons jusque là évité, autant que faire se peut, d’utiliser les termes complexes de la PF. Cependant, il y en a certains que l’on aura tôt fait de croiser. Autant donc savoir de quoi il s’agit.
Les functors ou foncteurs en français, constituent une notion qui provient directement de la théorie des catégories en mathématiques. On va éviter de rentrer dans le détail de la définition mathématiques et tenter d’expliquer contrètement en quoi ils consistent en PF.
Un functor est un type mettant à disposition un utilitaire map permettant l’usage d’une fonction sur ladite valeur et qui préserve la composition.
Si la valeur en question est composée, c’est à dire qu’elle est un ensemble de valeurs individuelles (un tableau par exemple), alors le functor utilise l’opérateur pour exécuter la fonction sur toutes les valeurs individuellement.
Tout cela semble très complexe, mais vous connaissez déjà des functors dans la pratique. .map en est l’exemple parfait. On pourrait imaginer un functor sur une chaine de caractères qui mettrait les lettres en majuscule :
// cette fonction fait la même chose que .toUpperCase()
// mais pour l'exemple, on l'implémente comme un functor
function uppercaseLetter(c) {
let code = c.charCodeAt(0);
// lowercase letter?
if (code >= 97 && code <= 122) {
// uppercase it!
code = code - 32;
}
return String.fromCharCode(code);
}
function stringMap(mapperFn,str) {
return [...str].map(mapperFn).join('');
}
stringMap(uppercaseLetter, 'Hello World!'); // HELLO WORLD!Les array sont donc nativement des functors, mais il ne tient qu’à vous d’implémenter vos propres foncteurs lorsqu’ils paraissent adaptés à la situation.
Monad
De même que les foncteurs, la monade provient directement de la théorie des catégories en mathématiques. Comme nous n’avons pas l’intention de faire un doctorat en maths, tentons de comprendre les bases d’une monade sans s’encombrer de toute la théorie académique.
De la même manière que certains types – commes les arrays en JS – sont des foncteurs, on peut voir la monade comme un type de valeur. Le fait d’être un array (type) présuppose que l’on dispose de certaines méthodes et propriétés sur ce type de valeur : map(), pop(), push(), length. Nul besoin de vérifier, par convention, tout développeur sait de quelles méthodes et propriétés il dispose pour une valeur d’un type donné. Il en va de même aves les monades.
Par exemple, le nombre 42 possède un type, Number, qui lui confère certaines méthodes et propriétés. '42', peut sembler assez similaire, cependant, son type est cette fois String et cela lui confère d’autres méthodes et propriétés.
Une monade est un type, une structure de données contenant des comportements predéfinis. Les comportements prédéfinis la font ressembler à une interface. Ainsi, pour un développeur habitué à la PF, la lecture du code est améliorée car il sait d’après le nom de la monade les comportements qu’elle embarque.
En d’autres termes, une monade est la manière fonctionelle d’organiser divers comportements autour d’une valeur, un peu comme un objet permet d’encapsuler valeurs et comportements en POO.
Cependant, contrairement à un objet de POO, une monade se doit de comporter un minimum de méthodes et de garantir leur comportement. Ce minimum commun à toutes les monades est étendu pour créer des monades plus spécifiques. Cela fait que l’usage des monades est prédictible car le développeur fonctionnel en connait l’implémentation.
Si tout ce que l’on dit jusque là vous semble inutilement barbare et compliqué, sachez que jQuery est une monade [en]. Une monade est caractérisée par le respect des trois lois monadiques :
- La monade est un conteneur – wrapper – autour d’un autre type ;
- La monade possède une fonction lui permettant de se wrapper elle-même dans d’autres types de données (typiquement d’autres types de monades) ;
- La monade doit pouvoir passer la ou les valeurs qu’elle contient à une autre fonction, dans la mesure où ladite fonction retourne une monade.
Ces trois règles donnent naissance à des méthodes communes à toute monade. Cependant, en l’absence d’une unique convention, leur nom peut varier. Ainsi, toutes les monades contiennent au minimum les méthodes map(), chain() (aussi appellée bind() ou flatMap()) et ap().
Parmi les monades les plus connues, nous rencontrerons régulièrement Just, Identity, IO, Maybe ou encore Either.
Just a monad
Entrons dans le concret en définissant une des monades les plus simples, aka Just. Cette dernière ne contient que le strict minimum lui permettant de se qualifier en tant que monade.
De même qu’il n’y a aucune convention concernant le nommage des méthodes, il n’y a pas non plus de convention concernant l’implémentation et la création des monades. On peut par exemple les créer en utilisant le mot-clef new ou en invocant une fonction.
Il est commun d’utiliser la méthode of() afin de placer une valeur dans un foncteur (et une monade). Cela permet l’usage d’une interface commune tout en évitant les complexités d’un constructeur et de l’usage de new.
Nous allons dans cette partie utiliser certaines méthodes de Ramda, aussi, pour suivre les exemples suivant, il vous sera plus facile d’utiliser la console Ramda directement.
function Just(val) {
this.__value = val;
};
Just.of = function (val) {
return new Just(val);
};
Just.prototype.map = function (f) {
return Just.of(f(this.__value));
};
Just.prototype.bind = function (f) {
return f(this.__value);
};
Just.prototype.ap = function (otherMonad) {
return otherMonad.map(this.__value);
};Découvrons maintenant l’usage de ces différentes méthodes.
map()
map exécute une fonction sur la valeur contenue puis retourne le résultat wrappé dans une nouvelle monade de même type.
const A = Just.of(10);
const B = A.map( v => v * 2 );
new Just(10).map( v => v * 5 );
B; // Just(20)
// on peut aussi directement chainer map
Just.of(1).map(v => v + 1); // Just(2)Tous les environnements n’afficheront pas forcement Just(xxx), Firefox et Node afficheront quelque chose comme {"__value": 20}. Cependant, tant que nous comprenons bien qu’il s’agit d’une valeur de type Just faisant office de conteneur, la manière dont l’output est écrit importe peu.
bind()
bind() fait sensiblement la même chose que map(), à la différence près que la valeur retournée est brute, c’est à dire non contenue dans une monade, on dit que bind() flatten (lisse ou aplatit en français) la monade. Cela permet le respect de la seconde règle monadique et évite de se retrouver avec des monades wrappées dans d’autres monades.
const A = Just.of(10);
const eleven = A.bind(v => v + 1);
eleven; // 11
const X = Just.of(100);
const Y = Just.of(20);
// fonction qui retourne une monade
const multY = x => Y.map(v => v * x);
X.map(multY); // Just(Just(2000))
// bind prend ici tout son sens
X.bind(multY); // Just(2000)ap()
ap(), quoi qu’un peu plus complexe à appréhender que les deux méthodes précédentes, trouve néanmoins vite son utilité.
Ainsi que nous l’avons vu tout au long de cet article, la PF a constamment recourt aux fonctions d’ordre supérieur. Une fonction étant une valeur comme une autre, il est courant qu’une monade contienne une fonction pour valeur. Il nous faut donc une version de map() qui soit en mesure d’exécuter ladite fonction sur la valeur d’une autre monade.
Pour illustrer ap(), nous allons reprendre l’exemple précédent en utilisant une fonction multiply currifiée. Cela va nous permettre d’adopter un style point free.
const X = Just.of(100);
const Y = Just.of(20);
const multY = Y.map(multiply);
multY; // Just(curried function)
multY.ap(X); // Just(2000)Étant donné que map() retourne une monade, multY est une monade contenant la fonction multiply à laquelle a déjà été passée un premier argument.
Dès lors, l’appel de multY.ap(X) permet d’exécuter la fonction curryfiée en lui passant comme second argument la valeur contenue dans la monade X.
Just, aussi parfois nommée Identity est assez limitée. Cette monade fait juste office de conteneur pour une valeur. Cependant, en tant que monade la plus simple, elle est à la base de toutes les autres monades.
Maybe ?
Étant donné qu’il serait possible de consacrer un article entier au sujet des monades, on abordera seulement Maybe dans un exemple concret. Ainsi que mentionné précédemment, il en existe bien d’autres mais une fois que vous en avez compris le principe, vous les appréhenderez facilement.
Prenoms un exemple concret pour illustrer l’intérêt de Maybe. Nous avons un site sur lequel nous voulons personnaliser l’image d’en-tête en fonction de la région de l’utilisateur.
Nous avons donc une liste de bannières correspondant à chaque région :
const banners = {
'ara': '/assets/ara.jpg',
'bfc': '/assets/bfc.jpg',
'bre': '/assets/bre.jpg',
'cvl': '/assets/cvl.jpg',
'cor': '/assets/cor.jpg',
'ges': '/assets/ges.jpg',
'hdf': '/assets/hdf.jpg',
'idf': '/assets/idf.jpg',
'nor': '/assets/nor.jpg',
'naq': '/assets/naq.jpg',
'occ': '/assets/occ.jpg',
'pdl': '/assets/pdl.jpg',
'pac': '/assets/pac.jpg'
};Et les utilisateurs sont stockés dans un objet de la forme suivante :
const user = {
email: 'john@doe.com',
accountDetails: {
address: {
street: '6 rue de la Liberté',
city: 'Lyon',
region: 'pac',
postcode: '69006'
}
},
preferences: {}
};Avec un code classique, le problème se résout assez simplement.
function getUserBanner(banners, user) {
return banners[user.accountDetails.address.region];
}
getUserBanner(banners, user); // "/assets/pac.jpg"
// on peut même partir sur une approche fonctionnelle
// avec l'aide de quelques outils de PF (outils de Ramda)
const getUserBannerF = compose(
identity,
path(['accountDetails', 'address', 'region'])
);
getUserBannerF(user, banners); // "/assets/pac.jpg"Génial ! Sauf que tout ne se passe pas toujours comme prévu. L’utilisateur peut provenir des DOM-TOM, n’être pas français ou simplement n’avoir pas renseigné tous les détails de son compte. On peut gérer ça avec quelques conditions.
// on s'assure ici que le user ainsi que les champs requis existent
function getUserBanner(banners, user) {
if ((user !== null)
&& (user.accountDetails !== undefined)
&& (user.accountDetails.address !== undefined)) {
return banners[user.accountDetails.address.region];
}
}Malheureusement, en l’état, il n’est plus possible d’avoir du point free et on perd tout de même en lisibilité. Voyons comment Maybe peut nous sortir de là.
Maybe est assez simple à appréhender. Elle retourne comme Just dans le cas où une valeur est présente et retourne null (ce qui correspond à la monade Nothing) lorsqu’aucune valeur n’est présente. En outre, map ne tentera pas d’exécuter de fonction en l’absence de valeur. Cela évite toute génération d’erreur (et donc les vérifications en amont).
function Maybe(val) {
this.__value = val;
};
Maybe.of = function (val) {
return new Maybe(val);
};
Maybe.prototype.isNothing = function() {
return (this.__value === null || this.__value === undefined);
};
Maybe.prototype.map = function(f) {
if (this.isNothing()) return Maybe.of(null);
return Maybe.of(f(this.__value));
};
Maybe.prototype.join = function() {
return this.__value;
};
Maybe.prototype.bind = function(f) {
const res = this.map(f);
if (res.join() instanceof Object) return res.join();
return res;
};
Maybe.prototype.ap = function (otherMonad) {
return otherMonad.map(this.__value);
};
Maybe.prototype.orElse = function (def) {
if (this.isNothing()) return Maybe.of(def);
return this;
};On voit que Maybe possède une méthode isNothing() qui sert pour la structure de contrôle dans map ainsi que join() qui permet simplement de retourner la valeur unwrappée. On se sert de cette dernière méthode pour implémenter bind().
Ainsi, dans le cas où Maybe ne contient rien, bind() appelant map(), rien ne sera exécuté mais null sera retourné. En outre, dans ce dernier cas, étant donné que la valeur n’est pas dans deux niveaux de conteneurs, on n’exécute pas join(), sans quoi elle ne serait plus wrappée dans Maybe du tout.
Enfin, nous avons une méthode orElse() qui permet d’obtenir une valeur par défaut si la valeur d’entrée ne convient pas.
Grâce à Maybe, nous pouvons donc refactoriser notre code de la sorte :
function getUserBannerF(banners, user) {
return Maybe.of(user)
.map(path(['accountDetails', 'address', 'region']))
.map(prop(__, banners));
}
getUserBannerF(banners, user); // Maybe('/assets/pac.jpg')
getUserBannerF(banners, {}); // Maybe(null)Je pense qu’une explication s’impose pour l’usage de R.__. Cette méthode de Ramda permet une application partielle pour toute méthode curryfiée.
Ainsi, lors de l’exécution du second map, la fonction prop est appellée comme ceci prop(__, banners)('pac'), ce qui équivaut à prop('pac', banners).
Admettons que nous voulions maintenant bénéficier d’une fonction dédiée à l’obtention de la province.
function getProvinceBanner(province) {
return Maybe.of(banners[province]);
}
function getUserBannerF(user) {
return Maybe.of(user)
.map(path(['accountDetails', 'address', 'region']))
.bind(getProvinceBanner);
}
getUserBannerF(user); // Maybe('/assets/pac.jpg')
getUserBannerF(emptyUser).orElse('/assets/default.jpg'); // Maybe('/assets/default.jpg')Et voilà, nous retrouvons l’utilité de notre méthode bind(). Nous n’allons pas ici utiliser ap() car cela rallongerait d’autant cette partie.
Néanmoins, sachez que si nous voulons mettre la source de notre bannière dans le DOM, la monade IO est toute indiquée. Dès lors, la méthode ap() s’imposerait pour faire travailler les deux monades de concert.
Conclusion
Comme dit en début d’article, le JavaScript n’est pas un langage conçu pour être 100% fonctionnel. Il est possible de faire du fonctionnel en JS et même du 100% fonctionnel en s’adjoignant l’aide de quelques outils, mais j’ai parfois la sensation qu’on traverstit l’esprit et le paradigme du JS.
Il s’agit là vraiment de mon opinion. J’ai ainsi tendance à prendre les bonnes parties de la PF et de les appliquer à mon code sans essayer de tendre vers du fonctionel au sens académique du terme. Si tel est le but, mieux vaut peut-être se diriger vers un langage fonctionel qui compile vers JavaScript.
Outils & ressources
Selon le degré de PF que vous souhaitez insufler à votre code, il vous faudra adjoindre quelques outils à JavaScript afin de vous faciliter la tâche.
- Ramda est à mon sens vraiment un incontournable, elle facilite le currying, l’application partielle, la composition etc ;
- Immutable.js et Mori permettent toutes deux d’utiliser des structures de données persistantes sans sacrifier les performances ;
- Si vous désirez utiliser les monades, monet.js offre les monades les plus communes et vous évite ainsi de tout implémenter vous-même ;
- eslint-plugin-fp est, comme son nom l’indique, un plugin pour ESlint qui vous permet d’adapter l’outil pour le JavaScript fonctionnel.
Au rang des ressources pour approfondir le sujet, je conseille la lecture de Functional Light JavaScript ainsi que le livre Mostly Adequate Guide to Functional Programming, lequel explique en profondeur la théorie derrière chaque concept.
En outre, comme certains termes de FP sont un peu barbarres, il est toujours utile de conserver une référence des termes [en] sous la main.
Enfin, voici une liste assez fournie contenant de multiples ressources et outils à propos de la PF. N’hésitez pas à l’explorer !
Commentaires
Rejoignez la discussion !