Collecter et grapher les métriques serveurs avec Sensu et Grafana
À chaque type de monitoring ses objectifs et ses outils. Si les checks permettent d’être alertés en temps réel sur un dysfonctionnement, les graphiques donnent un aperçu sur le long terme du comportement de nos serveurs. Ils permettent aussi d’en prévoir l’évolution. Voyons comment collecter les métriques importantes et créer des graphiques pertinents avec Grafana.
Comme nous l’avons vu dans la définition de notre plan de monitoring, une politique de monitoring complète s’articule autour de trois axes : les logs, les checks et les métriques. Nous allons dans cet article mettre en place le troisième volet de notre stratégie.
De nombreux outils permettent de collecter les métriques. En ce qui nous concerne, Sensu est déjà utilisé pour les checks, nous allons donc en tirer parti également pour la collection de métriques. Pour ceux qui n’auraient pas lu l’article sur la mise en place de health checks avec Sensu, je vous invite à le parcourir car nous ne re-détaillerons pas ici l’installation de ce dernier.
Les outils
Dans notre trousse à outil du parfait “monitoreur”, nous avons déjà installé Sensu et ses dépendances, à savoir Redis et Uchiwa. Je l’avais rapidement abordé dans l’article précédent, Sensu permet de collecter les métriques, mais il n’est ni en mesure de les stocker, ni de les afficher.
Pour palier à ces manques, nous allons nous entourer de deux briques supplémentaires : InfluxDB et Grafana.
Le premier, dont nous nous servirons comme moteur de stockage, est une base de données spécialement conçue pour les données temporelles. Ainsi, chaque ligne est constituée d’une ou plusieurs informations (charge CPU, datacenter, hôte…) et d’un timestamp. C’est la solution idéale pour stocker nos métriques. En outre, sa syntaxe est très proche du SQL, ceux qui connaissent déjà ce langage ne seront donc pas perdus.
Vous en conviendrez, visualiser les métriques directement dans la base de données est assez limitant. C’est pourquoi nous nous adjoignons la puissance d’un autre outil : Grafana. Ce dernier permet de requêter des bases de données afin de créer des graphiques. Vous créez vos propres requêtes pour que les graphiques révèlent ce que vous voulez, c’est d’une puissance incroyable.
Installation
L’installation est assez simple, nous utiliserons les packets Debian pour profiter des mises à jour ultérieures.
# nous avons besoin de apt-transport-https qui n'est pas toujours installé
apt-get install -y apt-transport-https
# ajout de la clef apt et du dépôt à nos sources
curl -sL https://repos.influxdata.com/influxdb.key | apt-key add -
echo "deb https://repos.influxdata.com/debian jessie stable" | tee /etc/apt/sources.list.d/influxdb.list
# reload des sources et installation d'influx client et serveur
apt-get update
apt-get install influxdb influxdb-client
# meme procédure pour grafana, clef, sources, reload et installation
curl https://packagecloud.io/gpg.key | apt-key add -
echo "deb https://packagecloud.io/grafana/stable/debian/ wheezy main" | tee /etc/apt/sources.list.d/influxdb.list
apt-get update
apt-get install grafanaVoilà, tout ce petit monde est bien installé sur notre serveur. Passons aux réglages. Influx est installé et préconfiguré pour se lancer au démarrage, ce n’est cependant pas le cas de Grafana, remédions à cela :
# systemd pour les dernière versions
# (Debian 8, Ubuntu 16.04 et dérivés)
systemctl enable grafana-server.service
# initD pour les autres
update-rc.d grafana-server defaults 95 10Grafana est une application web composé d’un backend en Go et d’un front en Angular. Par défaut, Grafana écoute sur le port 3000… le même port que Uchiwa, nous allons donc modifier ça afin de pouvoir faire tourner les deux sur le même serveur. J’ai choisi le port 4000 de manière complètement arbitraire, libre à vous d’en utiliser un autre si ça vous sied.
Dans le fichier de configuration, nous allons aussi définir un login et un mot de passe afin de sécuriser la connexion. Enfin, nous allons désactiver la possibilité de s’enregistrer pour les utilisateurs ne possédant pas de compte (un admin devra leur en créer un au besoin). Le fichier de conf se trouve à /etc/grafana/grafana.ini.
# un petit coup de sed pour plus de rapidité
sed -i 's/;http_port = 3000/http_port = 4000/' /etc/grafana/grafana.ini
sed -i 's/;admin_user = admin/admin_user = mon_login/' /etc/grafana/grafana.ini
sed -i 's/;admin_password = admin/admin_password = mon_mdp/' /etc/grafana/grafana.ini
sed -i 's/;allow_sign_up = true/allow_sign_up = false/' /etc/grafana/grafana.iniInfluxDB permet d’ajouter des données de plusieurs manières, par le client CLI évidemment, mais également via des requêtes HTTP ou en ouvrant un port UDP. Cette dernière méthode est évidemment la plus performante de par la nature même d’UDP, mais également parce qu’Influx tire profit du buffer UDP pour grouper l’écriture des données.
Par défaut aucun port n’est ouvert en UDP. Pour configurer cela, rendez-vous dans la section [[udp]] du fichier de config /etc/influxdb/influxdb.conf.
[[udp]]
enabled = true
bind-address = ":8090"
database = "sensu"
# retention-policy = ""
# These next lines control how batching works. You should have this enabled
# otherwise you could get dropped metrics or poor performance. Batching
# will buffer points in memory if you have many coming in.
batch-size = 1000 # will flush if this many points get buffered
batch-pending = 5 # number of batches that may be pending in memory
batch-timeout = "1s" # will flush at least this often even if we haven't hit buffer limitNous configurons Influx pour écouter en UDP sur le port 8090 et nous spécifions que toutes les requêtes arrivants sur ce port serons écrites dans la base de données “sensu”. Enfin, tel que directement spécifié dans les commentaires nous activons quelques options de performances.
Vous noterez qu’Influx n’est ici absolument pas sécurisé et qu’il est exposé sur le réseau notamment à cause des protocoles UDP et HTTP. Le plus sûr est de fermer tous les ports via iptables.
Influx possède une interface web que je ne trouve pas être d’une singulière utilité, je la désactive donc dans la config.
[admin]
enabled = falseGrafana et Influx sont maintenant configurés, il ne reste qu’à les démarrer.
service influxdb start
service grafana startDernier point de la configuration, il faut créer la fameuse base de données “sensu” et lui attribuer une politique de rétention.
# en passant par la CLI
# taper juste influx pour démarrer l'interpréteur
> CREATE DATABASE sensu
> CREATE RETENTION POLICY a_year ON sensu DURATION 365d REPLICATION 1 DEFAULT
# puis exit pour sortir
# la même chose en utilisant le protocole http (plus facile à scripter)
curl http://localhost:8086/query?q=CREATE+DATABASE+"sensu"
curl http://localhost:8086/query?q=CREATE+RETENTION+POLICY+"a_year"+ON+"sensu"+DURATION+"365d"+REPLICATION+1+DEFAULTVous avez directement pu constater avec ces quelques commandes que la syntaxe est assez familière du SQL.
Pour revenir un peu en détail sur la politique de rétention, Influx permet de définir une durée après laquelle les informations sont effacées. Par défaut, elles ne le sont jamais, j’ai configuré ici un an. Comme le monitoring va constamment alimenter votre base de données, il y a un moment où vous aller arriver à saturation de votre espace disque.
En fonction du nombre de serveurs monitorés, de la quantité de données que vous collectez et de la durée de conservation que vous souhaitez appliquer (est-ce réellement utile de conserver les données plusieurs années, voire mois ?) il faudra que vous définissiez l’espace disque nécessaire et la politique de rétention adaptée.
Par ailleurs, Influx permet aussi de faire du downsampling sur vos données. C’est à dire qu’au bout d’une période prédéfinie, vous autorisez Influx à éliminer des détails pour gagner en espace. Par exemple, au lieu de conserver les données toutes les 10 secondes, après un mois vous ne conserverez que toutes les 5 minutes. Nous n’en parlerons pas ici mais tout est dans la doc.
Balance les données !
Il est temps de revenir à Sensu. Nous allons utiliser les metrics check pour collecter les données dont nous avons besoin. Ce type de check renvoie simplement des données texte que nous allons ensuite rediriger vers Influx. Une fois n’est pas coutume, il va falloir créer un check dans le langage de votre choix.
J’ai choisis de récolter les métriques suivantes :
- load cpu,
- utilisation de la mémoire (RAM et SWAP),
- une liste user defined de services avec leur conso RAM et CPU,
- l’IOPS des disques (read, write et total),
- le taux de remplissage des partitions,
- l’utilisation du réseau (up et down).
Pour ce faire, j’ai cette fois ci laissé tomber les scripts bash et j’ai créé un check en Nodejs. Petite particularité, pour écrire dans Influx via l’UDP, il faut que les données soient au format du line protocol.
# line protocol
[key] [fields] [timestamp]
# exemple
cpu_load,host=db1 value=14.45
# exemple avec deux tags
cpu_load,datacenter=us1,host=db1 value=14.76Si ce n’est pas déjà le cas, il va falloir installer Nodejs. La LTS du moment est la version 6, partons donc là dessus :
curl -sL https://deb.nodesource.com/setup_6.x | -E bash -
apt-get install -y nodejsSi vous souhaitez utilisez le même check que moi, il est disponible via npm. Vous trouverez les détails d’install sur la page GitHub.
Vous pouvez appeler directement le check en faisant node serverMetrics.js si vous vous trouvez dans le répertoire des plugins. Ça vous affichera juste les métriques au format line protocol dans la console.
Tout l’enjeu va maintenant être de rediriger cet output vers Influx. Pour cela, il va falloir définir un handler spécifique qui aura pour mission d’envoyer l’output du check en UDP sur le port que nous avons définis dans la config d’Influx (8090).
Le code est dispo sur un gist mais je le mets ici car sans lui, rien ne fonctionnera. Libre à vous cependant de le réécrire dans un autre langage si vous êtes plus à l’aise avec autre chose. Ce sont ici des choix très personnels.
# dans /etc/sensu/handlers/influx.js
#!/usr/bin/nodejs
const influxPort = 8090;
const dgram = require('dgram');
const client = dgram.createSocket('udp4');
let raw = '';
process.stdin.on('readable', () => {
let chunk = process.stdin.read();
if (chunk !== null) {
raw += chunk;
}
});
process.stdin.on('end', () => {
let json = JSON.parse(raw);
let result = json.check.output;
client.send(result, influxPort, 'localhost', (err) => {
client.close();
});
});Sensu va passer les donnée du check à notre handler via un pipe. Nous récupérons donc ici les données sur le stdin et les parsons (il s’agit de JSON). Sensu ajoute en effet d’autres informations au données du check, telles que le temps d’exécution etc. Nous n’en avons ici pas besoin, nous récupérons donc simplement l’ouput et nous l’envoyons sur le port UDP d’Influx.
Au cas où vous vous disiez “Pourquoi ne pas envoyer les données directement depuis le check ?”, la question mérite d’être posée. En effet, Sensu rajoute ici des données dont nous n’avons pas besoin, nous pourrions court-circuiter ça et tout faire directement dans le check. Au delà de la question de la “propreté” d’une telle solution, le fait de passer par le handler permet d’envoyer le résultat du check à travers le transport Sensu. Ce petit hack fonctionnerait pour monitorer le serveur Sensu, mais pour les autres, en local, il n’y a pas de serveur InfluxDB à l’écoute, ça ne marcherait donc pas. Fin de la parenthèse.
Nous avons notre check et notre handler, il ne reste plus qu’à faire communiquer tout ce petit monde. Nous avions créé dans l’article précédent un fichier qui déclare le handler pour l’email et Slack. Ajoutons lui un handler pour Influxdb :
{
"handlers": {
"default": {
"type": "set",
"handlers": ["notify"]
},
"notify": {
"type": "pipe",
"command": "/etc/sensu/handlers/notify.js",
},
"influxdb": {
"type": "pipe",
"command": "/etc/sensu/handlers/influx.js"
}
}
}Notre handler pipe tout simplement le résultat du check vers influx.js. Au cas où vous vous posiez également la question “Mais pourquoi n’utilise-t-on pas directement le handler UDP ?”. Rappelez vous qu’on veut juste l’output du check et non tout le JSON qui va avec…
Dernière étape pour alimenter notre base de données, configurer ce check. Direction /etc/sensu/checks :
# notre fichier est déjà peuplé de nombreux checks
# on ajoute notre metrics check
{
"checks": {
…
"collect_metrics": {
"type": "metric",
"command": "/etc/sensu/plugins/metrics.js",
"interval": 30,
"handlers": ["influxdb"],
"subscribers": ["default"]
}
}
}Rien de surprenant ici. On prendra la tension des serveurs toutes les 30 sec, à ajuster selon vos besoins. Rappelez-vous que plus vous le faites souvent, plus vous aurez besoin d’espace pour stocker vos métriques (ou moins vous les garderez longtemps) et plus votre serveur de monitoring sera sollicité.
Une fois n’est pas coutume, on s’assure que tous les fichiers appartiennent à Sensu, que les handlers et plugins sont exécutables et on redémarre.
chown -R sensu:sensu /etc/sensu
chmod 744 -R /etc/sensu/plugins
chmod 744 -R /etc/sensu/handlers
service sensu-server restartVous devriez constater dans Uchiwa que vous avez un nouveau check et vous aller voir InfluxDB se peupler.
influx
> USE sensu
> SHOW MEASUREMENTS
name: measurements
------------------
name
cpu_load
disk_rIOPS
disk_tIOPS
disk_wIOPS
fs_usage
network_rx
network_tx
process_cpu
process_mem
ram_used
swap_used
# voir le contenu d'un measurement
SELECT * FROM cpu_load [WHERE tag='nom_dun_host']
1465821976632440628 bm1 14.03
1465822006084582682 en2 0.03
1465822006628693385 bm1 14.03
1465822036093951174 en2 0.03
1465822036626170640 bm1 13.78
1465822066095415419 en2 0.03
1465822066630293860 bm1 14.03
1465822096081662400 en2 0.03
1465822096615752863 bm1 13.78
…On est toujours assez proche du SQL, mais Influx possède quand même quelques notions bien à lui. Jetez un œil aux concepts clefs pour en apprendre d’avantage.
Aussi, avant de passer à la partie Grafana, sachez qu’il est possible d’exploiter les données stockées dans Influx pour lever des alertes (remplissage des disques, charge moyenne des CPU sur les x dernières minutes etc.). J’ai pour cela créé un petit script qui est dispo sur ce Gist.
Graphe moi ça !
Okayyy, Sensu nourrit Influx de bonnes datas, il ne nous reste “plus” qu’à les rendre digeste avec de beaux graphiques. Pour commencer, il faut se loguer sur l’interface de Grafana. Direction http://adresse_ip_qui_va_bien:4000.
J’ai déjà fait un petit speech sur le nom de domaine et le reverse proxy dans l’article sur Sensu à propos de l’accès à Uchiwa, c’est la même chose ici. Admettez que http(s?)://graph.monsite.com est plus sexy que http://adresse_ip_à_retenir:4000 !
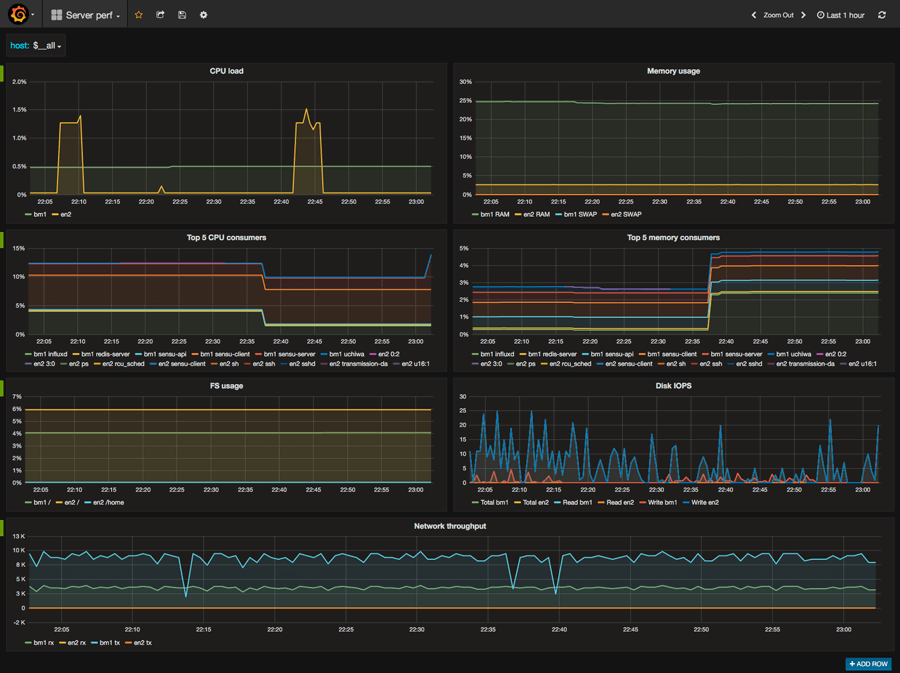
Source
La première chose à faire est de connecter InfluxDB à Grafana. En haut à gauche, cliquez sur l’icône Grafana puis allez dans data sources et enfin ajoutez une nouvelle source. Dans la mesure où notre base Influx est en local et ne requiert ni login ni mot de passe, c’est assez direct.
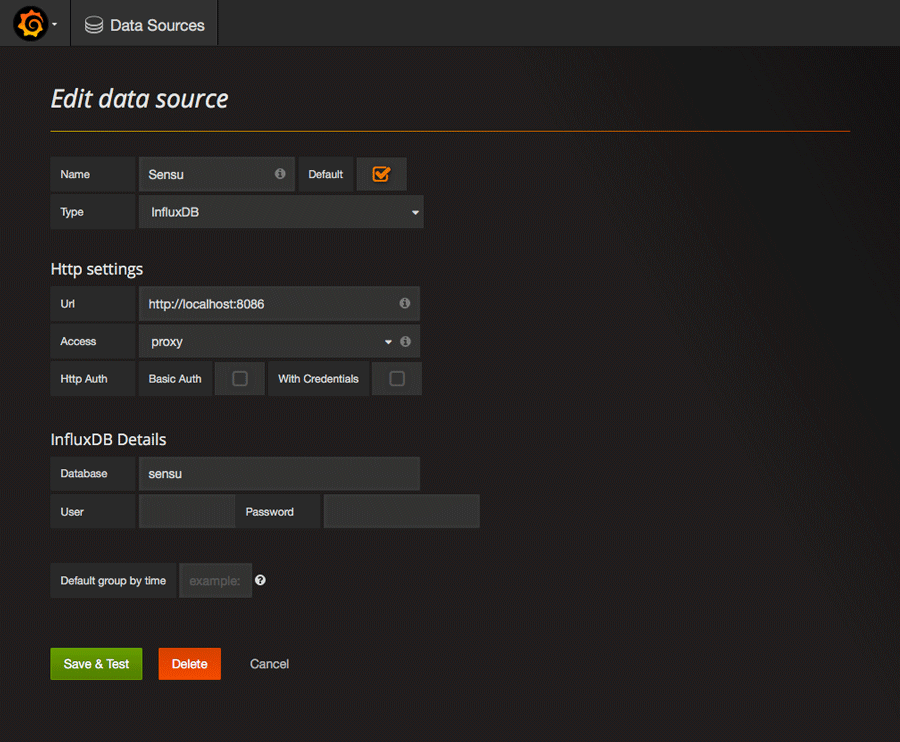
L’option proxy permet au serveur Grafana de requêter directement InfluxDB et d’envoyer le tout à votre navigateur. Sinon, votre navigateur fait directement les requêtes auprès d’Influx, mais comme dit plus haut, sans login ni mot de passe, vous avez plutôt intérêt à ne pas exposer Influx sur le réseau. Et si vous fermez les ports, alors Grafana devra faire les requêtes pour vous.
Templating
Une fois Influx et Grafana connectés, il faut créer un nouveau dashboard, lequel sera vide. Je ne vais pas expliquer ici toutes les notions, mais quelques une des plus importantes. Commençons par le templating. Cela permet d’automatiquement considérer par exemple nos différents hôtes dans nos requêtes, et de ce fait nos tableaux.
Rendez vous depuis votre nouveau dashboard (les templates sont liés aux dahsboards) sur la roue crantée puis cliquez sur “templating”. Là vous allez “expliquer” à Grafana que vous voulez que la variable “host” contiennent nos différents hôtes. Dans chaque measurement, nous avons définit un tag host qui fait référence au serveur concerné. En effet, si nous ne sommes pas en mesure de discerner les serveurs, les données ne veulent plus rien dire…
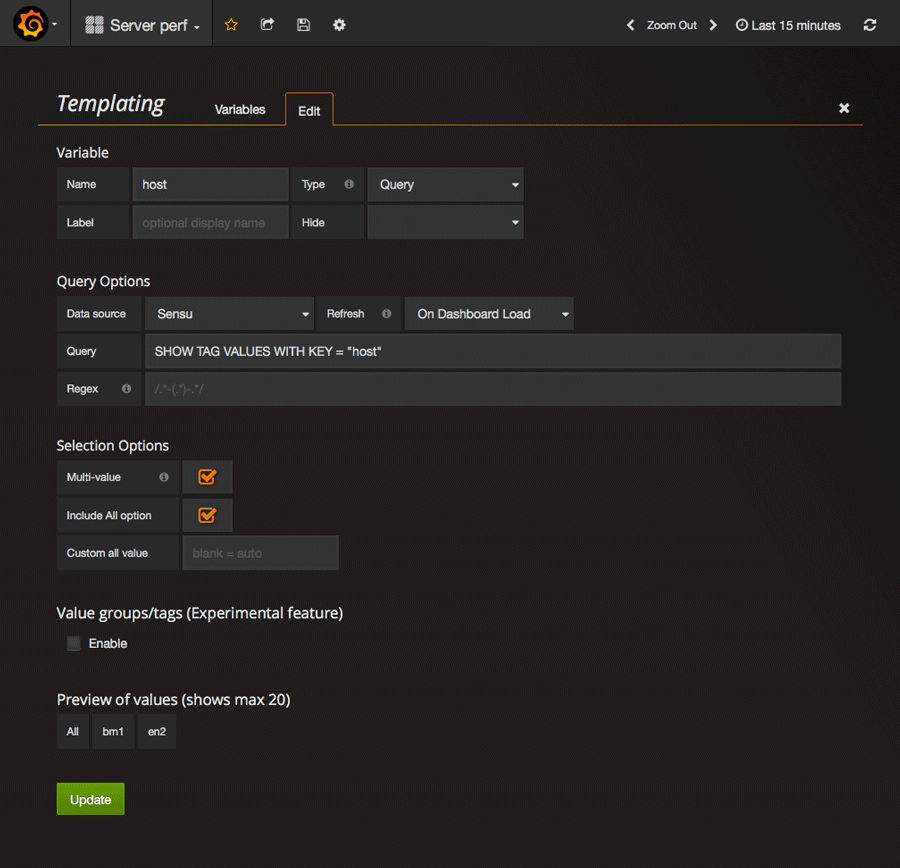
Rien d’ahurissant ici, il faut bien penser à paramétrer l’option refresh correctement, sinon vos nouveaux hôtes ne s’afficheront pas au fur et à mesure que votre infrastructure s’agrandit. Les options de sélections permettent quant à elle de définir s’il est possible de sélectionner plusieurs hôtes à la fois et d’avoir une option “afficher tout”.
Enfin, elle n’est pas activé dans la capture d’écran ci-dessus, mais l’option de tag est fort pratique puisqu’elle permet de sélectionner les serveurs pas tags ou groupes. En un clic, vous pourrez ensuite afficher tous vos serveurs de base de données, tous vos serveurs web etc.
Dashboard
Dernier point, mais non des moindres, la création de tableau. Tout se passe dans l’éditeur de requête. Comme vous pouvez le voir dans l’image ci-dessous, vous voudrez évidemment grouper par hôtes afin de pouvoir choisir dynamiquement vos hôtes. Il faut bien penser à échapper la variable host sans quoi ça ne fonctionnera pas.
Par ailleurs, par défaut, l’éditeur tente de grouper les données par intervalle de temps, lequel se définit juste au dessous. Dans le cas présent, comme je ne récupère les métriques que toutes les 30 secondes, il n’est pas nécessaire de les lisser plus encore. Enfin, les alias permettent d’obtenir des noms propres dans les légendes, les variables correspondent aux tags renseignés dans vos mesures. Toutes vos modifications doivent être sauvegardées avec ctr + s où en cliquant sur la petite icône disquette en haut du dash.
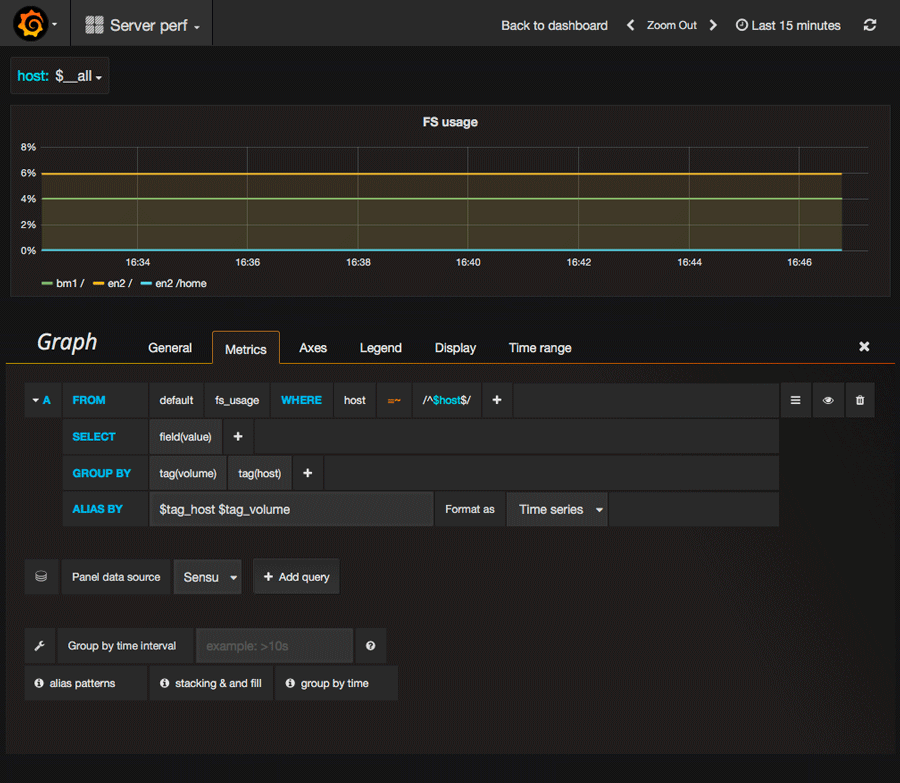
Pour le reste, c’est assez intuitif, je vous laisse jouer avec les différents onglets pour découvrir. Pour plus d’infos, il faudra aller fouiller la documentation, l’onglet référence est assez riche d’informations utiles.
Toute la configuration est en JSON et vous pouvez ainsi exporter vos tableaux pour pouvoir les restaurer plus tard ou les importer dans une autre installation. Si vous avez suivi de A à Z et que vous récoltez les mêmes métriques que moi, vous pouvez importer mon dashboard et jouer avec les paramètres à partir de là.
Conclusion
Juste une petite parenthèse sur les performances, InfluxDB, de par l’usage qui en est fait, génère de nombreux I/O disques. C’est pourquoi la base de données a été conçue pour fonctionner avec des diques SSD. Pensez-y au moment de choisir votre serveur, ça pourrait avoir un impact considérable sur les performances. N’hésitez pas à vous référer à la partie hardware recommandations de la doc.
Vous êtes maintenant en possession des principales métriques en mesure de refléter les performances de vos serveurs et de votre infrastructure et vous avez un dashboard très visuel qui vous permet en un clin d’œil de savoir ce qui se passe. Libre à vous de l’étoffer ou d’en faire d’autres plus spécifiques.
En outre, Influx et Grafana seront tout à fait appropriés pour collecter des données plus orientées métier, telles que le nombre de connexions à une application, le nombre de tickets support ouverts, les commits git de vos équipes, bref, tout ce qui peut se grapher possède ici sa place. D’ailleurs n’hésitez pas à nous faire part des métriques et dashboard que vous mettez en place !
Commentaires
Rejoignez la discussion !